Программа «Tabula» была создана разработчиком Мануэлем Аристараном при поддержке ProPublica, LaNacionData и Knight-MozillaOpenNews. Несмотря на строго ограниченный функционал инструмента, он может стать одним из главных помощников при работе с большими объемами текстовых документов.
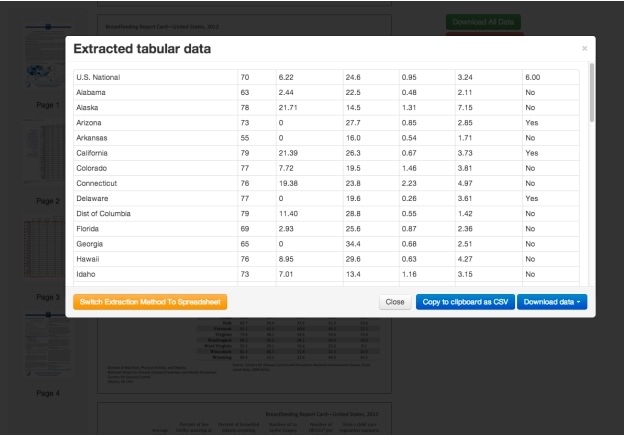
«Tabula» решает проблему недоступности табличных данных, хранящихся в PDF файлах. Пользователю больше не придется вручную переносить данные из таблиц в новый документ — программа предоставит их в специальном CSV формате.
Для получения табличных данных достаточно установить «Tabula» на компьютер, открыть PDF файл с нужными табличными данными и обвести их мышкой — программа предложит скопировать таблицу в CSV формате или скачать CSV или TSV.
«Tabula» доступна для всех версий ОС, для ее работы потребуется установить JAVA. Создатель программы предлагает программистам вместе поработать над ее усовершенствованием на GitHub.
Узнать подробнее о процессе установки и скачать «Tabula».


